
Migrating a Hadoop infrastructure to GCP
Migrating a Hadoop infrastructure to GCP
29 September 2020
The migration of an on-premises Hadoop solution to Google Cloud requires a shift in approach. A typical on-premises Hadoop system consists of a monolithic cluster that supports many more workloads across multiple business areas. As a result, the system becomes more complex. It can require administrators to make compromises to get everything working in the monolithic cluster. When you prepare to migrate Hadoop infrastructure to Google Cloud, you can reduce the administrative complexity. However for simplification and to get the most efficient way for processing in Google Cloud with minimal cost, you need to rethink how to structure your data and jobs.
The Dataproc service of GCP runs Hadoop, using a persistent Dataproc cluster to replicate your on-premises setup as it seems the easiest solution. However, there are some limitations to that approach:
- Keeping your data in a persistent HDFS cluster using Dataproc is more expensive than storing your data in Cloud Storage, which is what we recommend, as explained later. Keeping data in an HDFS cluster also limits your ability to use your data with other Google Cloud products.
- Augmentation or replacement of some open-source-based tools with other related Google Cloud services can be more efficient or economical for particular use cases.
- Using a single, persistent Dataproc cluster for your jobs it is more difficult to manage than shifting to targeted clusters that serve individual jobs or job areas.
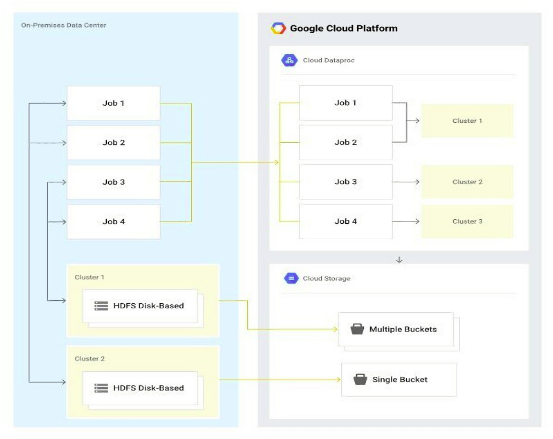
The flexible way for migrating your Hadoop system to Google Cloud is to shift away from thinking in terms of large, multi-purpose, persistent clusters. You store your data in the Cloud Storage to support multiple, temporary processing clusters.
- It provides Built-in support for Hadoop. The data proc service of google is used to manage Hadoop and Spark environments. Dataproc can be used to run existing jobs, no need to move away from all of the Hadoop tools.
- It manages hardware and configuration. While running Hadoop on Google Cloud, you never need to worry about physical hardware. You specify the configuration of the cluster and Dataproc allocates resources for it hence can scale clusters at any time.
- It simplifies version management. Updating the open-source tools and working together comes under managing a Hadoop cluster. While using Dataproc, much of that work is managed by Dataproc versioning.
- It provides flexibility in job configuration. An on-premises Hadoop setup uses a single cluster serving many purposes. When you move to Google Cloud create as many clusters as you need. This makes it easy to maintain the complexity of a single cluster with growing dependencies and software configuration interactions.
Migrating our Hadoop data lake requires highly configured hardware. Security monitoring and cost control are two main areas in which we’ll continue to invest.
Not only is data stored using different datastore technologies or not stored at all in the case of streaming data, but data is also spread across the teams’ GCP projects. It provides Built-in support for Hadoop. The data proc service of google is used to manage Hadoop and Spark environments. Dataproc can be used to run existing jobs, no need to move away from all of the Hadoop tools.
It manages hardware and configuration. While running Hadoop on Google Cloud, you never need to worry about physical hardware. You specify the configuration of the cluster and Dataproc allocates resources for it hence can scale clusters at any time.
It simplifies version management. Updating the open-source tools and working together comes under managing a Hadoop cluster. While using Dataproc, much of that work is managed by Dataproc versioning.
It provides flexibility in job configuration. An on-premises Hadoop setup uses a single cluster serving many purposes. When you move to Google Cloud create as many clusters as you need. This makes it easy to maintain the complexity of a single cluster with growing dependencies and software configuration interactions.
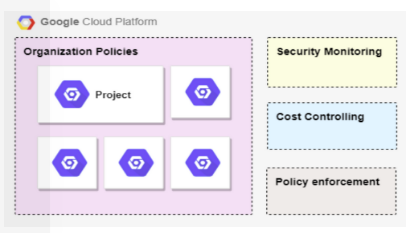
Migrating our Hadoop data lake to the cloud is a bold decision—but we are totally satisfied with how it turned out and how quickly we were able to pull it off. The freedom of a cloud environment enjoyed by autonomous teams comes with the challenge of global transparency. Security monitoring and cost control are two main areas in which we will continue to invest. A further pressing is metadata management. Not only is data stored using different datastore technologies or not stored at all in the case of streaming data, but data is also spread across the projects.